OptimaLab: Transformer with Independent Subnetwork Training
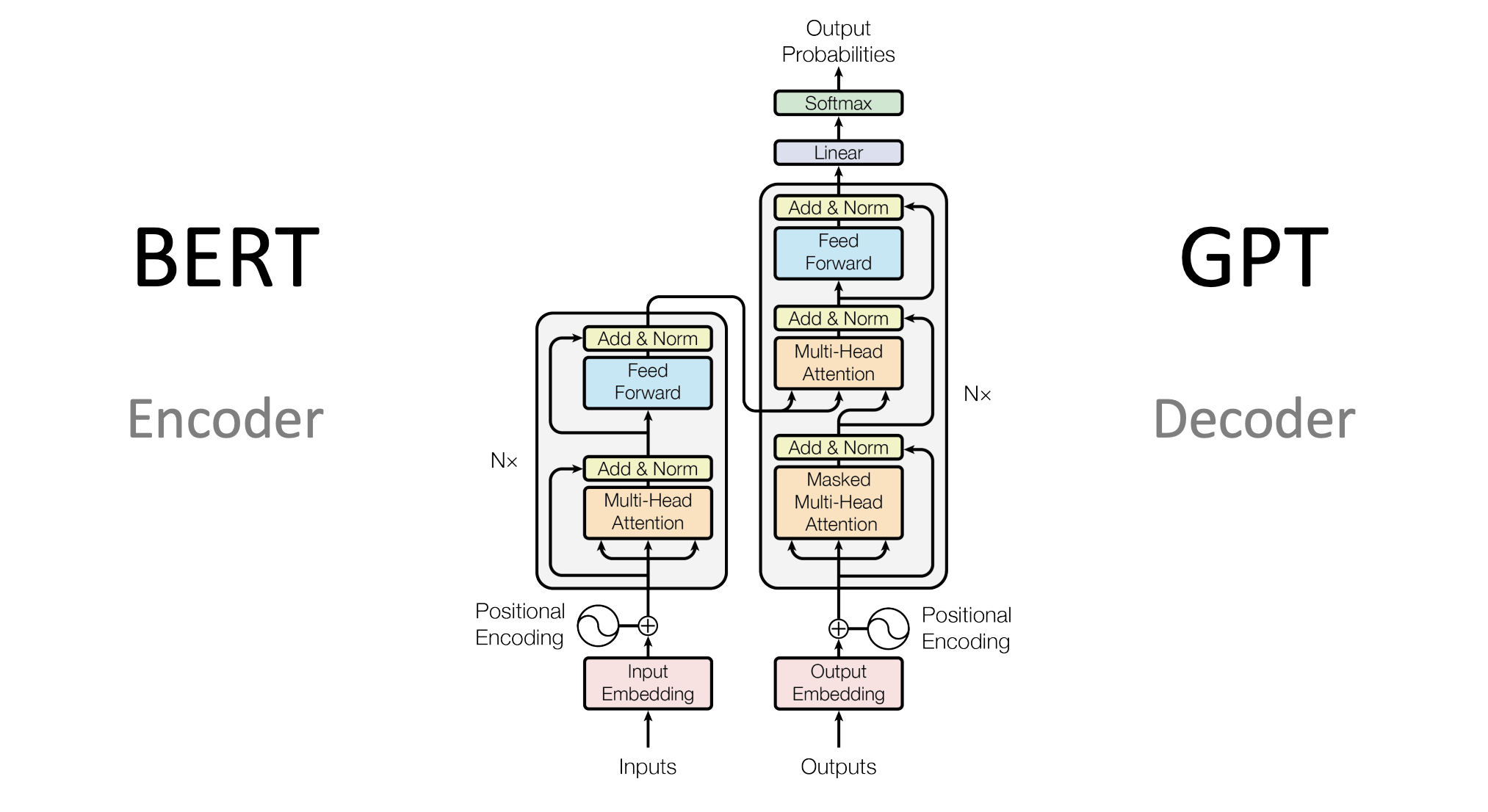
This research project seeks to evaluate the effectiveness of Independent Subnetwork Training (IST) methods on the Transformer architecture. A transformer is a type of neural network that is often used for natural language processing. Transformers are made up of attention heads which are modules that “learn” how which “words” in a sentence are “important.”
To explain exactly what this research project does, I will first explain machine learning in general. Machine learning tries to develop a mathematical model that can be used to predict a function’s output given an input by observing the function’s behavior on a subset of inputs. The simplest model is a line: \(y = mx + b\). Training this simple model on a dataset is often called “linear regression.” To fit our line to a dataset, we take a bath of input data, pass it through the model, see how far off predictions are and adjust the value of \(m\) and \(b\) accordingly. This process is called “gradient descent.” With multidimensional data, our model becomes \(y = Ax + b\). A neural network is a composition of linear and non-linear functions. Simply composing linear functions results in a linear function which isn’t capable of capturing the relationships found in non-linear data.
A transformer is a specific type of large matrix-vector function. Transformer with Independent Subnetwork Training (TwIST) tries to take the matrices in the model, partition them into smaller matrices, arranging the smaller matrices into subnetworks, training the subnetworks in parallel on separate GPUs, and recombining the subnetworks back into the large original network. We hope that TwIST will provide a fast method to train large models on small devices.
What I did
I carried on Chen’s work by taking his algorithm and implementing it. Chen orginally made a proof-of-concept by simulating the process of creating subnetworks and communicating them to the GPUs by copying the full model to each GPU and masking parameters locally. In contrast, I wrote the code to actually carry out the algorithm at the system level. This included writing the partitioning code and communication code.
The partitioning code is pretty interesting in that to ensure that attention heads were roughly evenly distributed among the workers (GPUs), I formulated the algorithm as a statistics problem. We have \(n\) hats (GPUs) and we have \(k\) colors of balls (unique attention heads). Each hat has a quota of \(m\). We want to place the balls into the hats such that no two balls of the same color are in the same hat and that together the hats have all the colors. To do this, we line up the hats in a circle, placing balls one-by-one in each hat rotating through the colors. Now, we have ensured that together the hats contain all the colors. Next, we simply fill up the rest of the hat by taking the colors not currently in the hat and randomly selecting the remaining.
The communication code is less interesting but was very complex to implement as the transformer architecture is a complicated one.
What I used
I used Python with Pytorch for implementing the algorithm, Bash for executing the scripts, and Python Plotly for visualizing the results.
Challenges
This research has helped develop my capabilities to work on and understand large codebases. When I first got on the project, the codebase was wildly underdoccumetated and it was difficult to figure out what it was trying to do. The sheer scale of the codebase helped me understand the importance of writing clear code, choosing intuitive variable names, and adding documentation to every function.
Copyright: Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)
Author: Chen Dun, Tasos Kyrillidis, Michael Menezes, Hamza Shili, Barbara Su
Posted on: February 13, 2024